
 Twitter
Twitter Slack
Slack GitHub
GitHubDocumentation
Introduction
Configuration
- HTTPProxy Fundamentals
- Ingress v1 Support
- Virtual Hosts
- Inclusion and Delegation
- TLS Termination
- Upstream TLS
- Request Routing
- External Service Routing
- Request Rewriting
- CORS
- Websockets
- Upstream Health Checks
- Client Authorization
- TLS Delegation
- Rate Limiting
- Access logging
- Cookie Rewriting
- Overload Manager
- JWT Verification
- Annotations Reference
- Slow Start Mode
- API Reference
Deployment
- Deployment Options
- Contour Configuration
- Upgrading Contour
- Enabling TLS between Envoy and Contour
- Redeploy Envoy
Guides
- Deploying Contour on AWS with NLB
- AWS Network Load Balancer TLS Termination with Contour
- Deploying HTTPS services with Contour and cert-manager
- External Authorization Support
- FIPS 140-2 in Contour
- Using Gatekeeper with Contour
- Using Gateway API with Contour
- Global Rate Limiting
- Configuring ingress to gRPC services with Contour
- Health Checking
- How to enable structured JSON logging
- Creating a Contour-compatible kind cluster
- Collecting Metrics with Prometheus
- How to Configure PROXY Protocol v1/v2 Support
- Contour/Envoy Resource Limits
Troubleshooting
- Envoy Administration Access
- Contour Debug Logging
- Envoy Debug Logging
- Visualize the Contour Graph
- Show Contour xDS Resources
- Profiling Contour
- Contour Operator
Resources
- Support Policy
- Compatibility Matrix
- Contour Deprecation Policy
- Release Process
- Frequently Asked Questions
- Tagging
Security
Contribute
Redeploying Envoy
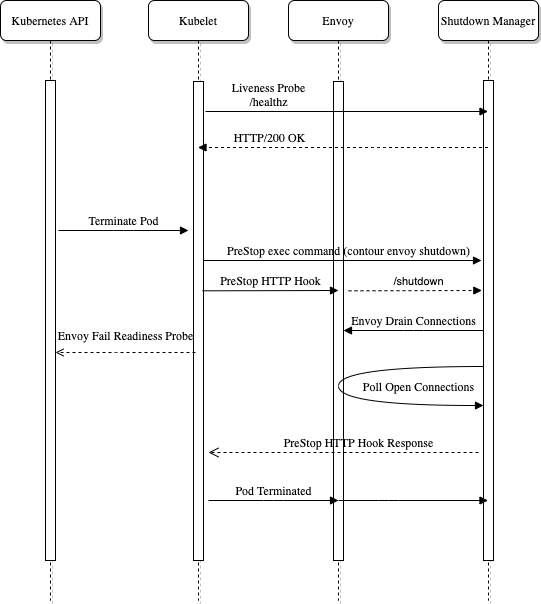
The Envoy process, the data path component of Contour, at times needs to be re-deployed. This could be due to an upgrade, a change in configuration, or a node-failure forcing a redeployment.
When implementing this roll out, the following steps should be taken:
- Stop Envoy from accepting new connections
- Start draining existing connections in Envoy by sending a
POSTrequest to/healthcheck/failendpoint - Wait for connections to drain before allowing Kubernetes to
SIGTERMthe pod
Overview
Contour implements an envoy sub-command named shutdown-manager whose job is to manage a single Envoy instances lifecycle for Kubernetes.
The shutdown-manager runs as a new container alongside the Envoy container in the same pod.
It exposes two HTTP endpoints which are used for livenessProbe as well as to handle the Kubernetes preStop event hook.
- livenessProbe: This is used to validate the shutdown manager is still running properly. If requests to
/healthzfail, the container will be restarted. - preStop: This is used to keep the Envoy container running while waiting for connections to drain. The
/shutdownendpoint blocks until the connections are drained.
- name: shutdown-manager
command:
- /bin/contour
args:
- envoy
- shutdown-manager
image: ghcr.io/projectcontour/contour:main
imagePullPolicy: Always
lifecycle:
preStop:
exec:
command:
- /bin/contour
- envoy
- shutdown
livenessProbe:
httpGet:
path: /healthz
port: 8090
initialDelaySeconds: 3
periodSeconds: 10
The Envoy container also has some configuration to implement the shutdown manager.
First the preStop hook is configured to use the /shutdown endpoint which blocks the Envoy container from exiting.
Finally, the pod’s terminationGracePeriodSeconds is customized to extend the time in which Kubernetes will allow the pod to be in the Terminating state.
The termination grace period defines an upper bound for long-lived sessions.
If during shutdown, the connections aren’t drained to the configured amount, the terminationGracePeriodSeconds will send a SIGTERM to the pod killing it.
Shutdown Manager Config Options
The shutdown-manager runs as another container in the Envoy pod.
When the pod is requested to terminate, the preStop hook on the shutdown-manager executes the contour envoy shutdown command initiating the shutdown sequence.
The shutdown manager has a single argument that can be passed to change how it behaves:
| Name | Type | Default | Description |
|---|---|---|---|
| integer | 8090 | Port to serve the http server on | |
| string | /admin/ok | File to poll while waiting shutdown to be completed. |
Shutdown Config Options
The shutdown command does the work of draining connections from Envoy and polling for open connections.
The shutdown command has a few arguments that can be passed to change how it behaves:
| Name | Type | Default | Description |
|---|---|---|---|
| duration | 5s | Time interval to poll Envoy for open connections. | |
| duration | 0s | Time wait before polling Envoy for open connections. | |
| duration | 0s | Time wait before draining Envoy connections. | |
| integer | 0 | Min number of open connections when polling Envoy. | |
| integer | 9001 | Deprecated: No longer used, Envoy admin interface runs as a unix socket. | |
| string | /admin/admin.sock | Path to Envoy admin unix domain socket. | |
| string | /admin/ok | File to write when shutdown is completed. |
 Edit
Edit